Linear map
In mathematics, a linear map (also called a linear mapping, linear transformation or, in some contexts, linear function) is a mapping V → W between two modules (including vector spaces) that preserves (in the sense defined below) the operations of addition and scalar multiplication.
An important special case is when V = W, in which case the map is called a linear operator,[1] or an endomorphism of V. Sometimes the term linear function has the same meaning as linear map, while in analytic geometry it does not.
A linear map always maps linear subspaces onto linear subspaces (possibly of a lower dimension);[2] for instance it maps a plane through the origin to a plane, straight line or point. Linear maps can often be represented as matrices, and simple examples include rotation and reflection linear transformations.
In the language of abstract algebra, a linear map is a module homomorphism. In the language of category theory it is a morphism in the category of modules over a given ring.
Contents
1 Definition and first consequences
2 Examples
3 Matrices
4 Examples of linear transformation matrices
5 Forming new linear maps from given ones
6 Endomorphisms and automorphisms
7 Kernel, image and the rank–nullity theorem
8 Cokernel
8.1 Index
9 Algebraic classifications of linear transformations
10 Change of basis
11 Continuity
12 Applications
13 See also
14 Notes
15 References
Definition and first consequences
Let V{textstyle V}





f(u+v)=f(u)+f(v){displaystyle f(mathbf {u} +mathbf {v} )=f(mathbf {u} )+f(mathbf {v} )}  | additivity / operation of addition |
f(cu)=cf(u){displaystyle f(cmathbf {u} )=cf(mathbf {u} )}  | homogeneity of degree 1 / operation of scalar multiplication |
Thus, a linear map is said to be operation preserving. In other words, it does not matter whether you apply the linear map before or after the operations of addition and scalar multiplication.
This is equivalent to requiring the same for any linear combination of vectors, i.e. that for any vectors u1,…,un∈V{textstyle mathbf {u} _{1},ldots ,mathbf {u} _{n}in V}

- f(c1u1+⋯+cnun)=c1f(u1)+⋯+cnf(un).{displaystyle fleft(c_{1}mathbf {u} _{1}+cdots +c_{n}mathbf {u} _{n}right)=c_{1}fleft(mathbf {u} _{1}right)+cdots +c_{n}fleft(mathbf {u} _{n}right).}

Denoting the zero elements of the vector spaces V{textstyle V}




- f(0V)=f(0v)=0f(v)=0W.{displaystyle fleft(mathbf {0} _{V}right)=fleft(0mathbf {v} right)=0f(mathbf {v} )=mathbf {0} _{W}.}

Occasionally, V{textstyle V}



A linear map V→K{textstyle Vto mathbf {K} }
These statements generalize to any left-module RM{textstyle {}_{R}M}

Examples
- The zero map x ↦ 0 between two left-modules (or two right-modules) over the same ring is always linear.
- The identity map on any module is a linear operator.
- Any homothecy centered in the origin of a vector space, v↦cv{textstyle vmapsto cv}
where c is a scalar, is a linear operator. This does not hold in general for modules, where such a map might only be semilinear.
- For real numbers, the map x ↦ x2 is not linear.
- For real numbers, the map x ↦ x + 1 is not linear (but is an affine transformation; y = x + 1 is a linear equation, as the term is used in analytic geometry.)
- If A is a real m × n matrix, then A defines a linear map from Rn to Rm by sending the column vector x ∈ Rn to the column vector Ax ∈ Rm. Conversely, any linear map between finite-dimensional vector spaces can be represented in this manner; see the following section.
Differentiation defines a linear map from the space of all differentiable functions to the space of all functions. It also defines a linear operator on the space of all smooth functions.- The (definite) integral over some interval I is a linear map from the space of all real-valued integrable functions on I to R.
- The (indefinite) integral (or antiderivative) with a fixed starting point defines a linear map from the space of all real-valued integrable functions on R to the space of all real-valued, differentiable, functions on R. Without a fixed starting point, an exercise in group theory will show that the antiderivative maps to the quotient space of the differentiables over the equivalence relation, "differ by a constant", which yields an identity class of the constant valued functions (∫: I(ℜ) → D(ℜ)/ℜ){textstyle left(,int !: I(Re ) to D(Re )/Re ,right)}
.
- If V and W are finite-dimensional vector spaces over a field F, then functions that send linear maps f : V → W to dimF(W) × dimF(V) matrices in the way described in the sequel are themselves linear maps (indeed linear isomorphisms).
- The expected value of a random variable (which is in fact a function, and as such a member of a vector space) is linear, as for random variables X and Y we have E[X + Y] = E[X] + E[Y] and E[aX] = aE[X], but the variance of a random variable is not linear.
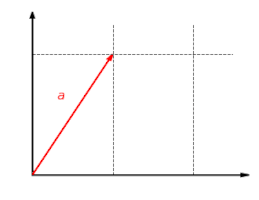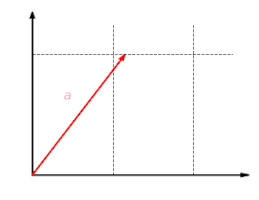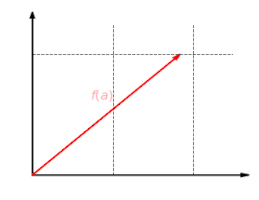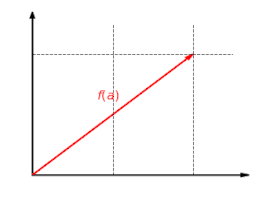
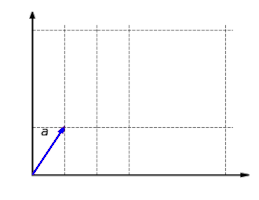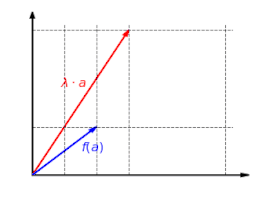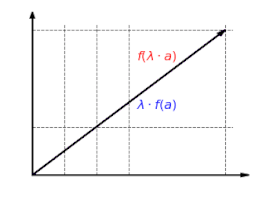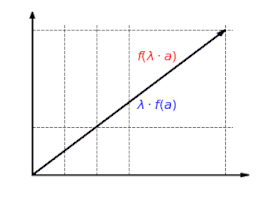
The function f:R2→R2{textstyle f:mathbb {R} ^{2}to mathbb {R} ^{2}}
with f(x,y)=(2x,y){textstyle f(x,y)=(2x,y)}
is a linear map. This function scales the x{textstyle x}
component of a vector by the factor 2{textstyle 2}
.
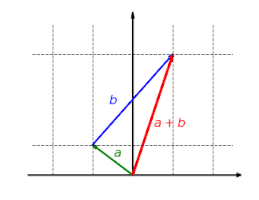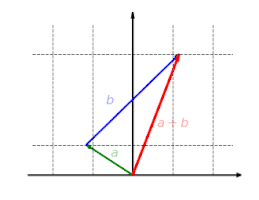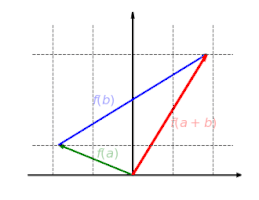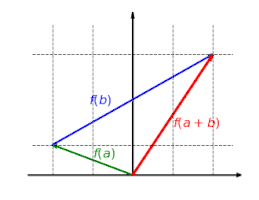
The function is additive: It doesn't matter whether first vectors are added and then mapped or whether they are mapped and finally added: f(a+b)=f(a)+f(b){textstyle f(a+b)=f(a)+f(b)}
The function is homogeneous: It doesn't matter whether a vector is first scaled and then mapped or first mapped and then scaled: f(λa)=λf(a){textstyle f(lambda a)=lambda f(a)}





Matrices
If V and W are finite-dimensional vector spaces and a basis is defined for each vector space, then every linear map from V to W can be represented by a matrix.[6] This is useful because it allows concrete calculations. Matrices yield examples of linear maps: if A is a real m × n matrix, then f(x) = Ax describes a linear map Rn → Rm (see Euclidean space).
Let {v1, …, vn} be a basis for V. Then every vector v in V is uniquely determined by the coefficients c1, …, cn in the field R:
- c1v1+⋯+cnvn.{displaystyle c_{1}mathbf {v} _{1}+cdots +c_{n}mathbf {v} _{n}.}

If f : V → W is a linear map,
- f(c1v1+⋯+cnvn)=c1f(v1)+⋯+cnf(vn),{displaystyle fleft(c_{1}mathbf {v} _{1}+cdots +c_{n}mathbf {v} _{n}right)=c_{1}fleft(mathbf {v} _{1}right)+cdots +c_{n}fleft(mathbf {v} _{n}right),}

which implies that the function f is entirely determined by the vectors f(v1), …, f(vn). Now let {w1, …, wm} be a basis for W. Then we can represent each vector f(vj) as
- f(vj)=a1jw1+⋯+amjwm.{displaystyle fleft(mathbf {v} _{j}right)=a_{1j}mathbf {w} _{1}+cdots +a_{mj}mathbf {w} _{m}.}

Thus, the function f is entirely determined by the values of aij. If we put these values into an m × n matrix M, then we can conveniently use it to compute the vector output of f for any vector in V. To get M, every column j of M is a vector
- (a1j⋯amj)T{displaystyle {begin{pmatrix}a_{1j}&cdots &a_{mj}end{pmatrix}}^{textsf {T}}}

corresponding to f(vj) as defined above. To define it more clearly, for some column j that corresponds to the mapping f(vj),
- M=( ⋯a1j⋯ ⋮amj){displaystyle mathbf {M} ={begin{pmatrix} cdots &a_{1j}&cdots \&vdots &\&a_{mj}&end{pmatrix}}}

where M is the matrix of f. In other words, every column j = 1, …, n has a corresponding vector f(vj) whose coordinates a1j, …, amj are the elements of column j. A single linear map may be represented by many matrices. This is because the values of the elements of a matrix depend on the bases chosen.
The matrices of a linear transformation can be represented visually:
- Matrix for T{textstyle T}
relative to B{textstyle B}
: A{textstyle A}
- Matrix for T{textstyle T}
: A′{textstyle A'}
- Transition matrix from B′{textstyle B'}
- Transition matrix from B{textstyle B}





Such that starting in the bottom left corner [v→]B′{textstyle left[{vec {v}}right]_{B'}}![{textstyle left[{vec {v}}right]_{B'}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eacd96761ada855ad5b966859fee8f9655a7ddef)
![{textstyle left[Tleft({vec {v}}right)right]_{B'}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/748437468b124fee67a0801c04390d4de1355e18)
![{textstyle A'left[{vec {v}}right]_{B'}=left[Tleft({vec {v}}right)right]_{B'}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b30a828a4a62a62e1d9698cb94b742b194447a86)

![{textstyle P^{-1}APleft[{vec {v}}right]_{B'}=left[Tleft({vec {v}}right)right]_{B'}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5885c2daeb2a65ea8500890571c596b15b89f6ae)
Examples of linear transformation matrices
In two-dimensional space R2 linear maps are described by 2 × 2 real matrices. These are some examples:
rotation
- by 90 degrees counterclockwise:
- A=(0−110){displaystyle mathbf {A} ={begin{pmatrix}0&-1\1&0end{pmatrix}}}
- A=(0−110){displaystyle mathbf {A} ={begin{pmatrix}0&-1\1&0end{pmatrix}}}
- by an angle θ counterclockwise:
- A=(cosθ−sinθsinθcosθ){displaystyle mathbf {A} ={begin{pmatrix}cos theta &-sin theta \sin theta &cos theta end{pmatrix}}}
- A=(cosθ−sinθsinθcosθ){displaystyle mathbf {A} ={begin{pmatrix}cos theta &-sin theta \sin theta &cos theta end{pmatrix}}}
- by 90 degrees counterclockwise:
reflection
- about the x axis:
- A=(100−1){displaystyle mathbf {A} ={begin{pmatrix}1&0\0&-1end{pmatrix}}}
- A=(100−1){displaystyle mathbf {A} ={begin{pmatrix}1&0\0&-1end{pmatrix}}}
- about the y axis:
- A=(−1001){displaystyle mathbf {A} ={begin{pmatrix}-1&0\0&1end{pmatrix}}}
- A=(−1001){displaystyle mathbf {A} ={begin{pmatrix}-1&0\0&1end{pmatrix}}}
- about the x axis:
scaling by 2 in all directions:
- A=(2002)=2I{displaystyle mathbf {A} ={begin{pmatrix}2&0\0&2end{pmatrix}}=2mathbf {I} }
- A=(2002)=2I{displaystyle mathbf {A} ={begin{pmatrix}2&0\0&2end{pmatrix}}=2mathbf {I} }
horizontal shear mapping:
- A=(1m01){displaystyle mathbf {A} ={begin{pmatrix}1&m\0&1end{pmatrix}}}
- A=(1m01){displaystyle mathbf {A} ={begin{pmatrix}1&m\0&1end{pmatrix}}}
squeeze mapping:
- A=(k001k){displaystyle mathbf {A} ={begin{pmatrix}k&0\0&{frac {1}{k}}end{pmatrix}}}
- A=(k001k){displaystyle mathbf {A} ={begin{pmatrix}k&0\0&{frac {1}{k}}end{pmatrix}}}
projection onto the y axis:
- A=(0001).{displaystyle mathbf {A} ={begin{pmatrix}0&0\0&1end{pmatrix}}.}
- A=(0001).{displaystyle mathbf {A} ={begin{pmatrix}0&0\0&1end{pmatrix}}.}








Forming new linear maps from given ones
The composition of linear maps is linear: if f : V → W and g : W → Z are linear, then so is their composition g ∘ f : V → Z. It follows from this that the class of all vector spaces over a given field K, together with K-linear maps as morphisms, forms a category.
The inverse of a linear map, when defined, is again a linear map.
If f1 : V → W and f2 : V → W are linear, then so is their pointwise sum f1 + f2 (which is defined by (f1 + f2)(x) = f1(x) + f2(x)).
If f : V → W is linear and a is an element of the ground field K, then the map af, defined by (af)(x) = a(f(x)), is also linear.
Thus the set L(V, W) of linear maps from V to W itself forms a vector space over K, sometimes denoted Hom(V, W). Furthermore, in the case that V = W, this vector space (denoted End(V)) is an associative algebra under composition of maps, since the composition of two linear maps is again a linear map, and the composition of maps is always associative. This case is discussed in more detail below.
Given again the finite-dimensional case, if bases have been chosen, then the composition of linear maps corresponds to the matrix multiplication, the addition of linear maps corresponds to the matrix addition, and the multiplication of linear maps with scalars corresponds to the multiplication of matrices with scalars.
Endomorphisms and automorphisms
A linear transformation f: V → V is an endomorphism of V; the set of all such endomorphisms End(V) together with addition, composition and scalar multiplication as defined above forms an associative algebra with identity element over the field K (and in particular a ring). The multiplicative identity element of this algebra is the identity map id: V → V.
An endomorphism of V that is also an isomorphism is called an automorphism of V. The composition of two automorphisms is again an automorphism, and the set of all automorphisms of V forms a group, the automorphism group of V which is denoted by Aut(V) or GL(V). Since the automorphisms are precisely those endomorphisms which possess inverses under composition, Aut(V) is the group of units in the ring End(V).
If V has finite dimension n, then End(V) is isomorphic to the associative algebra of all n × n matrices with entries in K. The automorphism group of V is isomorphic to the general linear group GL(n, K) of all n × n invertible matrices with entries in K.
Kernel, image and the rank–nullity theorem
If f : V → W is linear, we define the kernel and the image or range of f by
- ker(f)={x∈V:f(x)=0}im(f)={w∈W:w=f(x),x∈V}{displaystyle {begin{aligned}operatorname {ker } (f)&={,xin V:f(x)=0,}\operatorname {im} (f)&={,win W:w=f(x),xin V,}end{aligned}}}

ker(f) is a subspace of V and im(f) is a subspace of W. The following dimension formula is known as the rank–nullity theorem:
dim(ker(f))+dim(im(f))=dim(V).{displaystyle dim(ker(f))+dim(operatorname {im} (f))=dim(V).}[7]
The number dim(im(f)) is also called the rank of f and written as rank(f), or sometimes, ρ(f); the number dim(ker(f)) is called the nullity of f and written as null(f) or ν(f). If V and W are finite-dimensional, bases have been chosen and f is represented by the matrix A, then the rank and nullity of f are equal to the rank and nullity of the matrix A, respectively.
Cokernel
A subtler invariant of a linear transformation f:V→W{textstyle f:Vto W}
- coker(f):=W/f(V)=W/im(f).{displaystyle operatorname {coker} (f):=W/f(V)=W/operatorname {im} (f).}

This is the dual notion to the kernel: just as the kernel is a subspace of the domain, the co-kernel is a quotient space of the target.
Formally, one has the exact sequence
- 0→ker(f)→V→W→coker(f)→0.{displaystyle 0to ker(f)to Vto Wto operatorname {coker} (f)to 0.}

These can be interpreted thus: given a linear equation f(v) = w to solve,
- the kernel is the space of solutions to the homogeneous equation f(v) = 0, and its dimension is the number of degrees of freedom in a solution, if it exists;
- the co-kernel is the space of constraints that must be satisfied if the equation is to have a solution, and its dimension is the number of constraints that must be satisfied for the equation to have a solution.
The dimension of the co-kernel and the dimension of the image (the rank) add up to the dimension of the target space. For finite dimensions, this means that the dimension of the quotient space W/f(V) is the dimension of the target space minus the dimension of the image.
As a simple example, consider the map f: R2 → R2, given by f(x, y) = (0, y). Then for an equation f(x, y) = (a, b) to have a solution, we must have a = 0 (one constraint), and in that case the solution space is (x, b) or equivalently stated, (0, b) + (x, 0), (one degree of freedom). The kernel may be expressed as the subspace (x, 0) < V: the value of x is the freedom in a solution – while the cokernel may be expressed via the map W → R, (a,b)↦(a):{textstyle (a,b)mapsto (a):}
An example illustrating the infinite-dimensional case is afforded by the map f: R∞ → R∞, {an}↦{bn}{textstyle left{a_{n}right}mapsto left{b_{n}right}}


Index
For a linear operator with finite-dimensional kernel and co-kernel, one may define index as:
- ind(f):=dim(ker(f))−dim(coker(f)),{displaystyle operatorname {ind} (f):=dim(ker(f))-dim(operatorname {coker} (f)),}

namely the degrees of freedom minus the number of constraints.
For a transformation between finite-dimensional vector spaces, this is just the difference dim(V) − dim(W), by rank–nullity. This gives an indication of how many solutions or how many constraints one has: if mapping from a larger space to a smaller one, the map may be onto, and thus will have degrees of freedom even without constraints. Conversely, if mapping from a smaller space to a larger one, the map cannot be onto, and thus one will have constraints even without degrees of freedom.
The index of an operator is precisely the Euler characteristic of the 2-term complex 0 → V → W → 0. In operator theory, the index of Fredholm operators is an object of study, with a major result being the Atiyah–Singer index theorem.[8]
Algebraic classifications of linear transformations
No classification of linear maps could hope to be exhaustive. The following incomplete list enumerates some important classifications that do not require any additional structure on the vector space.
Let V and W denote vector spaces over a field, F. Let T: V → W be a linear map.
T is said to be injective or a monomorphism if any of the following equivalent conditions are true:
T is one-to-one as a map of sets.- kerT = {0V}
T is monic or left-cancellable, which is to say, for any vector space U and any pair of linear maps R: U → V and S: U → V, the equation TR = TS implies R = S.
T is left-invertible, which is to say there exists a linear map S: W → V such that ST is the identity map on V.
T is said to be surjective or an epimorphism if any of the following equivalent conditions are true:
T is onto as a map of sets.
coker T = {0W}
T is epic or right-cancellable, which is to say, for any vector space U and any pair of linear maps R: W → U and S: W → U, the equation RT = ST implies R = S.
T is right-invertible, which is to say there exists a linear map S: W → V such that TS is the identity map on W.
T is said to be an isomorphism if it is both left- and right-invertible. This is equivalent to T being both one-to-one and onto (a bijection of sets) or also to T being both epic and monic, and so being a bimorphism.- If T: V → V is an endomorphism, then:
- If, for some positive integer n, the n-th iterate of T, Tn, is identically zero, then T is said to be nilpotent.
- If T2 = T, then T is said to be idempotent
- If T = kI, where k is some scalar, then T is said to be a scaling transformation or scalar multiplication map; see scalar matrix.
Change of basis
Given a linear map which is an endomorphism whose matrix is A, in the basis B of the space it transforms vector coordinates [u] as [v] = A[u]. As vectors change with the inverse of B (vectors are contravariant) its inverse transformation is [v] = B[v'].
Substituting this in the first expression
- B[v′]=AB[u′]{displaystyle Bleft[v'right]=ABleft[u'right]}
![{displaystyle Bleft[v'right]=ABleft[u'right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2855717373418c2c2134151c0d0f4d5957292f8)
hence
- [v′]=B−1AB[u′]=A′[u′].{displaystyle left[v'right]=B^{-1}ABleft[u'right]=A'left[u'right].}
![{displaystyle left[v'right]=B^{-1}ABleft[u'right]=A'left[u'right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65eb8aa4babed0054fcf025303d23fd58309bf7e)
Therefore, the matrix in the new basis is A′ = B−1AB, being B the matrix of the given basis.
Therefore, linear maps are said to be 1-co- 1-contra-variant objects, or type (1, 1) tensors.
Continuity
A linear transformation between topological vector spaces, for example normed spaces, may be continuous. If its domain and codomain are the same, it will then be a continuous linear operator. A linear operator on a normed linear space is continuous if and only if it is bounded, for example, when the domain is finite-dimensional.[9] An infinite-dimensional domain may have discontinuous linear operators.
An example of an unbounded, hence discontinuous, linear transformation is differentiation on the space of smooth functions equipped with the supremum norm (a function with small values can have a derivative with large values, while the derivative of 0 is 0). For a specific example, sin(nx)/n converges to 0, but its derivative cos(nx) does not, so differentiation is not continuous at 0 (and by a variation of this argument, it is not continuous anywhere).
Applications
A specific application of linear maps is for geometric transformations, such as those performed in computer graphics, where the translation, rotation and scaling of 2D or 3D objects is performed by the use of a transformation matrix. Linear mappings also are used as a mechanism for describing change: for example in calculus correspond to derivatives; or in relativity, used as a device to keep track of the local transformations of reference frames.
Another application of these transformations is in compiler optimizations of nested-loop code, and in parallelizing compiler techniques.
See also
| Wikibooks has a book on the topic of: Linear Algebra/Linear Transformations |
- Affine transformation
- Linear equation
- Bounded operator
- Antilinear map
- Semilinear map
- Continuous linear operator
- Bent function
Notes
^ Linear transformations of V into V are often called linear operators on V Rudin 1976, p. 207
^ Rudin 1991, p. 14
Here are some properties of linear mappings Λ:X→Y{textstyle Lambda :Xto Y}whose proofs are so easy that we omit them; it is assumed that A⊂X{textstyle Asubset X}
and B⊂Y{textstyle Bsubset Y}
:
- Λ0=0.{textstyle Lambda 0=0.}
- If A is a subspace (or a convex set, or a balanced set) the same is true of Λ(A){textstyle Lambda (A)}
- If B is a subspace (or a convex set, or a balanced set) the same is true of Λ−1(B){textstyle Lambda ^{-1}(B)}
- In particular, the set:
- Λ−1({0})={x∈X:Λx=0}=N(Λ){displaystyle Lambda ^{-1}({0})={xin X:Lambda x=0}={N}(Lambda )}
is a subspace of X, called the null space of Λ{textstyle Lambda }.
- Λ−1({0})={x∈X:Λx=0}=N(Λ){displaystyle Lambda ^{-1}({0})={xin X:Lambda x=0}={N}(Lambda )}
- Λ0=0.{textstyle Lambda 0=0.}
^ Rudin 1991, p. 14. Suppose now that X and Y are vector spaces over the same scalar field. A mapping Λ:X→Y{textstyle Lambda :Xto Y}for all x,y∈X{textstyle x,yin X}
and all scalars α{textstyle alpha }
and β{textstyle beta }
. Note that one often writes Λx{textstyle Lambda x}
, rather than Λ(x){textstyle Lambda (x)}
, when Λ{textstyle Lambda }
^ Rudin 1976, p. 206. A mapping A of a vector space X into a vector space Y is said to be a linear transformation if: A(x1+x2)=Ax1+Ax2, A(cx)=cAx{textstyle Aleft({bf {{x}_{1}+{bf {{x}_{2}}}}}right)=A{bf {{x}_{1}+A{bf {{x}_{2}, A(c{bf {{x})=cA{bf {x}}}}}}}}}for all x,x1,x2∈X{textstyle {bf {{x},{bf {{x}_{1},{bf {{x}_{2}in X}}}}}}}
and all scalars c. Note that one often writes Ax{textstyle A{bf {x}}}
instead of A(x){textstyle A({bf {{x})}}}
if A is linear.
^ Rudin 1991, p. 14. Linear mappings of X onto its scalar field are called linear functionals.
^ Rudin 1976, p. 210
Suppose {x1,…,xn}{textstyle left{{bf {{x}_{1},ldots ,{bf {{x}_{n}}}}}right}}and {y1,…,ym}{textstyle left{{bf {{y}_{1},ldots ,{bf {{y}_{m}}}}}right}}
are bases of vector spaces X and Y, respectively. Then every A∈L(X,Y){textstyle Ain L(X,Y)}
determines a set of numbers ai,j{textstyle a_{i,j}}
such that
- Axj=∑i=1mai,jyi(1≤j≤n).{displaystyle A{bf {{x}_{j}=sum _{i=1}^{m}a_{i,j}{bf {{y}_{i}quad (1leq jleq n).}}}}}
It is convenient to represent these numbers in a rectangular array of m rows and n columns, called an m by n matrix:
- [A]=[a1,1a1,2…a1,na2,1a2,2…a2,n⋮⋮⋱⋮am,1am,2…am,n]{displaystyle [A]={begin{bmatrix}a_{1,1}&a_{1,2}&ldots &a_{1,n}\a_{2,1}&a_{2,2}&ldots &a_{2,n}\vdots &vdots &ddots &vdots \a_{m,1}&a_{m,2}&ldots &a_{m,n}end{bmatrix}}}
Observe that the coordinates ai,j{textstyle a_{i,j}}(with respect to the basis {y1,…,ym}{textstyle {{bf {{y}_{1},ldots ,{bf {{y}_{m}}}}}}}
) appear in the jth column of [A]{textstyle [A]}
. The vectors Axj{textstyle A{bf {x}}_{j}}
- Axj=∑i=1mai,jyi(1≤j≤n).{displaystyle A{bf {{x}_{j}=sum _{i=1}^{m}a_{i,j}{bf {{y}_{i}quad (1leq jleq n).}}}}}
^ Horn & Johnson 2013, 0.2.3 Vector spaces associated with a matrix or linear transformation, p. 6
^ Nistor, Victor (2001) [1994], "Index theory", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer Science+Business Media B.V. / Kluwer Academic Publishers, ISBN 978-1-55608-010-4.mw-parser-output cite.citation{font-style:inherit}.mw-parser-output q{quotes:"""""""'""'"}.mw-parser-output code.cs1-code{color:inherit;background:inherit;border:inherit;padding:inherit}.mw-parser-output .cs1-lock-free a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-limited a,.mw-parser-output .cs1-lock-registration a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-subscription a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration{color:#555}.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration span{border-bottom:1px dotted;cursor:help}.mw-parser-output .cs1-hidden-error{display:none;font-size:100%}.mw-parser-output .cs1-visible-error{font-size:100%}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-format{font-size:95%}.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-left{padding-left:0.2em}.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-right{padding-right:0.2em}: "The main question in index theory is to provide index formulas for classes of Fredholm operators ... Index theory has become a subject on its own only after M. F. Atiyah and I. Singer published their index theorems"
^ Rudin 1991, p. 15
1.18 Theorem Let Λ{textstyle Lambda }for some x∈X{textstyle xin X}
. Then each of the following four properties implies the other three:
Λ{textstyle Lambda }- The null space N(Λ){textstyle N(Lambda )}
is closed.
N(Λ){textstyle N(Lambda )}
Λ{textstyle Lambda }





![{displaystyle [A]={begin{bmatrix}a_{1,1}&a_{1,2}&ldots &a_{1,n}\a_{2,1}&a_{2,2}&ldots &a_{2,n}\vdots &vdots &ddots &vdots \a_{m,1}&a_{m,2}&ldots &a_{m,n}end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f53d08efeacd19a7270d82ee81484d772f4e8ef)
References
Halmos, Paul R. (1974). Finite-Dimensional Vector Spaces. New York: Springer-Verlag. ISBN 0-387-90093-4.
Horn, Roger A.; Johnson, Charles R. (2013). Matrix Analysis (Second ed.). Cambridge University Press. ISBN 978-0-521-83940-2.
Lang, Serge (1987), Linear Algebra (Third ed.), New York: Springer-Verlag, ISBN 0-387-96412-6
Rudin, Walter (1976). Principles of Mathematical Analysis (Third ed.). McGraw-Hill. ISBN 0-07-085613-3.
Rudin, Walter (1991). Functional Analysis (Second ed.). McGraw-Hill. ISBN 0-07-054236-8.
Linear algebra | ||
|---|---|---|
| Basic concepts |
|  |
| Vector algebra |
| |
| Multilinear algebra |
| |
| Matrices |
| |
Algebraic constructions |
| |
| Numerical |
| |
| ||


